I built an FP8 KV cache pool for mini-sglang, LMSYS’s reference SGLang implementation. The PR is at sgl-project/mini-sglang#132. 215 lines across 9 files; 135 of implementation, 80 tests and logging. No CUDA.
Results: memory capacity doubles at the same VRAM budget. Decode latency drops 5 to 27 percent depending on memory pressure. TTFT regresses 4 to 12 percent (fixable, follow-up PR queued). Quality holds: GSM8K-200 is 42.5% (fp8) vs 41.0% (fp16, within noise), NIAH perfect at 8k context. All on RTX 4060; expect larger speed and throughput gains on Hopper (H100) or higher due to greater memory bandwidth bottleneck.
I chose mini-sglang specifically because it’s small — 5,000 lines of Python with real attention backends — small enough to understand end-to-end, but complete enough to reveal what a real serving stack looks like. The full SGLang codebase would have been noise.
What a KV cache is, and why FP8
Every time a transformer generates a token, it looks back at every previous token’s key (K) and value (V) vectors to decide what to say next. K and V never change once written, so we cache them rather than recompute every step. The cache grows linearly with conversation length and gets read every decode step.
The arithmetic is sobering. A 7B model in fp16 uses roughly 0.5 MB of cache per token, so a 4,000-token conversation eats 2 GB before the model weights are even considered, and 32 concurrent users at that length need 64 GB of cache alone. In LLM serving at any reasonable scale, the KV cache is usually the dominant memory consumer, which is what makes it such an attractive target.
FP8 halves the bytes per token by storing K and V in 8-bit floating point instead of 16-bit. The trade-off is precision, and the whole question of this project is whether the resulting quantisation noise actually hurts quality.
Of the two FP8 variants, E4M3 (4 exponent, 3 mantissa) wins for KV cache because K and V values after RoPE are precision-bound rather than range-bound, and every production attention kernel (FlashAttention, FlashInfer, TRT-LLM) standardises on E4M3 for this reason.
Why quantise just the cache, not the whole model
Three things in inference can be quantised independently: weights (fixed parameters, read every forward pass), activations (transient intermediates within one forward step), and the KV cache (K and V that persist across decode steps and grow with context).
The cache is the only one that both persists and grows. For a 7B model serving 32 users at 4k context each, the cache is 64 GB while weights are 14 GB, so the cache is overwhelmingly the bottleneck. Quantising weights doesn’t fix that.
The other reason KV cache quant appealed to me is the small blast radius. The analogy I keep coming back to is that you do every calculation in full precision on a calculator and write the result in your notebook to five significant figures. The arithmetic itself is never lossy; only the storage is. Compute precision stays at fp16, model weights untouched, no calibration data needed (v1 ships scale=1.0), no kernel rewrite needed (existing attention kernels handle fp8 KV via a dtype dispatch). It’s a storage-layer change in one new pool class.
Full inference quantisation (W8A8, W4A8, FP4) is a much bigger undertaking, needing a calibrated checkpoint, accuracy studies, and matmul kernels for the quantised format. KV cache quant is the smallest disciplined change addressing the largest memory consumer, which felt like the right place to start.
The fp16 baseline
Before measuring anything about fp8, I needed to know what the system looked like in fp16. I ran 18 trials across 7 workload configurations on two model sizes.
With 8 GiB of VRAM and --memory-ratio 0.85 (the fraction of free GPU memory the engine claims for weights, workspace, and cache combined), Qwen3-0.6B gets 4.69 GiB of cache budget, which holds 43,928 tokens.
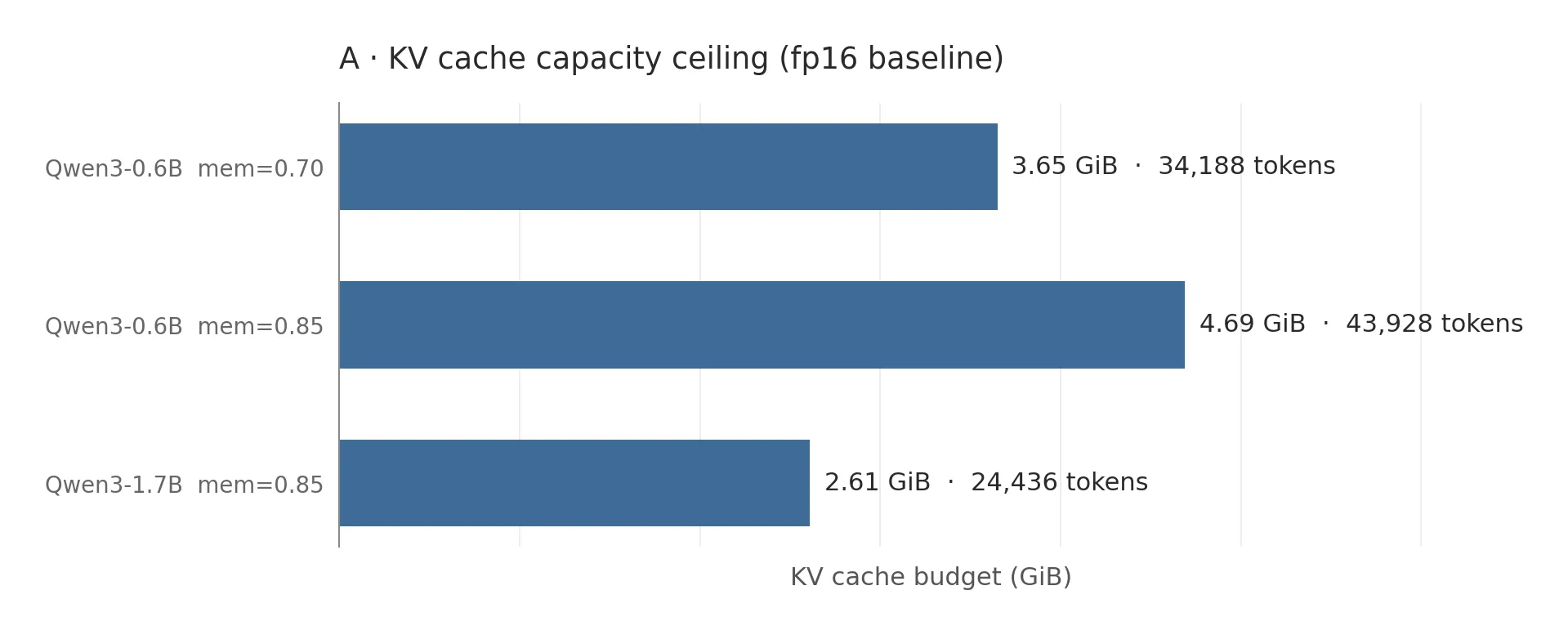
That number evaporates quickly under load: ten users at 4k context each is enough to fill it, so the cache really is the choke point at modest scale.
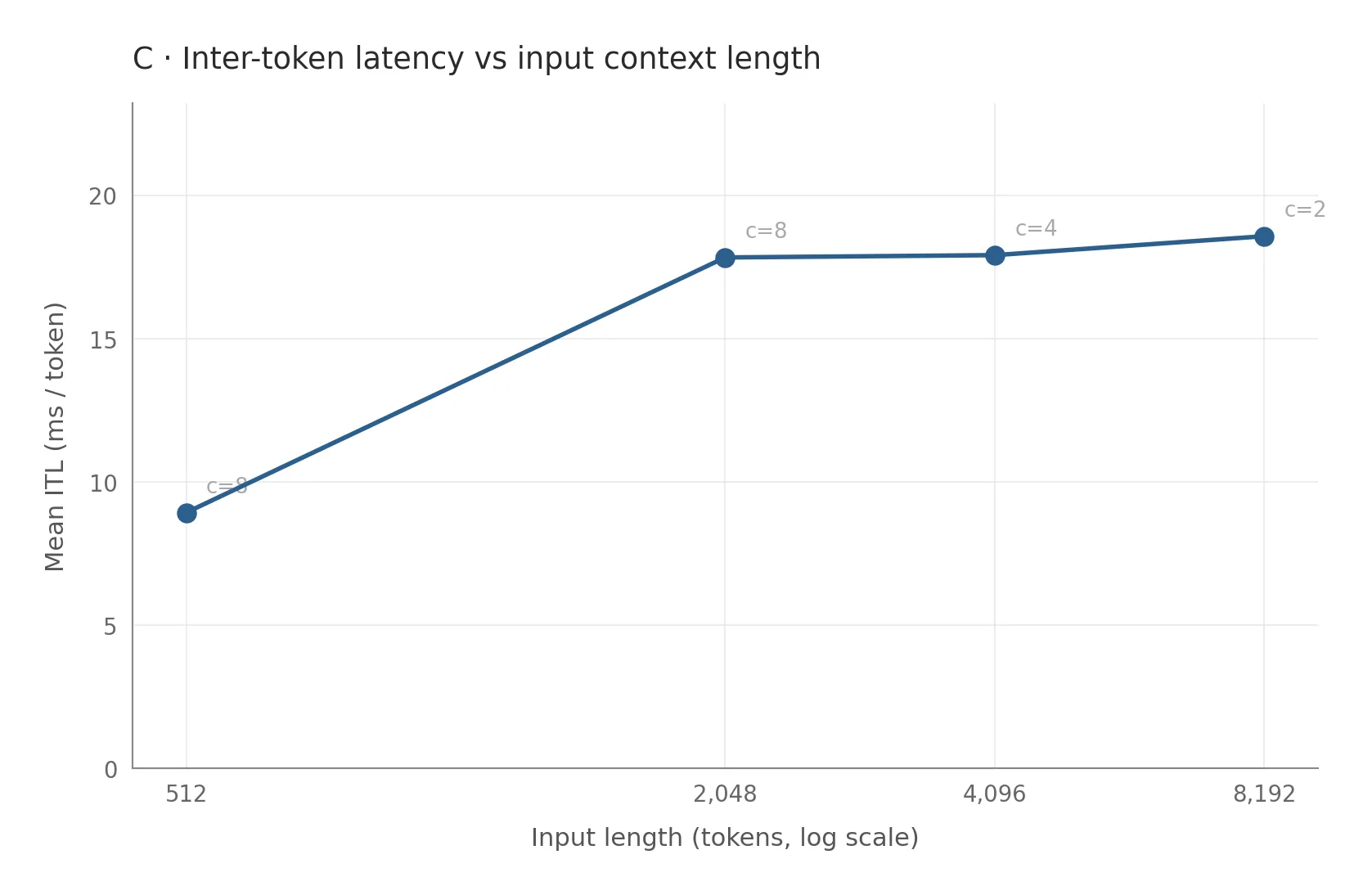
Inter-token latency (ITL, the time to produce each token after the first) grows steadily with context, climbing from about 9 ms at 512-token context to 18 ms by 2,048. As context grows, the read of accumulated K and V from HBM starts to dominate, and decode transitions from compute-bound to memory-bound. This is exactly where FP8 should help.
Time to first token tells a different story:
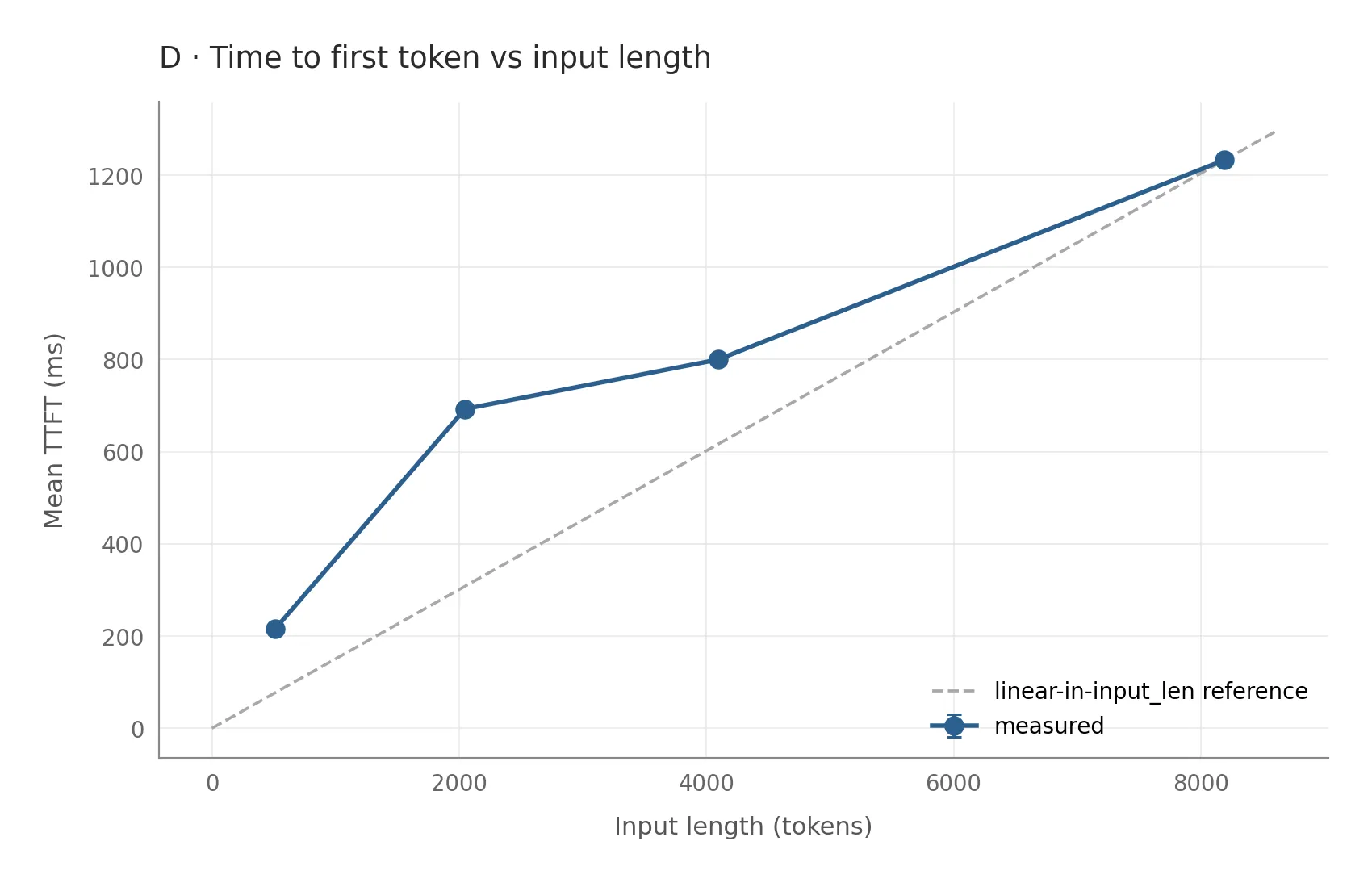
Prefill is dominated by the QKV matrix multiply rather than cache I/O, so halving cache bandwidth shouldn’t help here at all. I wanted to know this going in, so I’d be honest about where fp8 wins and where it doesn’t. With three trials per config and standard deviations under 1 percent, single-digit deltas later would be real signal.
Two plans, and I picked the disciplined one
I drew up two plans before starting. The ambitious one was around 400 lines: full calibration infrastructure to read per-tensor scales from W8A8 checkpoints, all three backends, comprehensive CLI surface for scale and calibration knobs. The disciplined one was around 70 lines: scale fixed at 1.0, FlashInfer as the primary path with the others as smoke tests, and a single --kv-dtype float8 flag with no calibration knobs.
I picked the disciplined plan. The plumbing is the contribution. Once store_dtype exists as an abstraction and the factory routes through the right pool, adding calibrated scales becomes a small additive follow-up. Getting the abstractions right in 70 lines mattered more than feature-completeness.
Before writing any code, though, I wanted to validate the assumptions. This turned out to be the most important hour of the project.
Phase 0: a ten-minute test that saved me days of debugging
The design rested on one assumption I’d absorbed from blog posts and documentation: that tensor.to(torch.float8_e4m3fn) is a saturating cast, clipping out-of-range values to plus or minus 448.
Five-line test, before any pool code:
x = torch.tensor([0.0, 1.0, 100.0, 500.0, -500.0, float('inf')],
dtype=torch.float16, device='cuda')
print(x.to(torch.float8_e4m3fn).to(torch.float16))
# tensor([0., 1., 96., nan, nan, nan])The cast is not saturating. Any fp16 value above 448 becomes fp8 NaN. Infinity becomes NaN.
Catching this before any pool code went in mattered. Without the clamp, every K or V outlier in real inference would silently fill the cache with NaN: an intermittent bug correlated with input distribution, invisible in any short integration test, and exactly the failure mode that costs days to diagnose in production.
The fix is one extra operation: k.clamp(-448, 448).to(torch.float8_e4m3fn). Infinities saturate, NaN stays NaN (which is correct; don’t invent a finite value from NaN input). A regression test now pins the behaviour. The habit I take from this: ask of any plan what the one assumption is that, if wrong, invalidates everything downstream — then find the cheapest possible test for it.
Phase minus one: hardware forces a gate
I also inspected each attention backend’s function signature before writing pool code. All three accept fp8 KV via the cache tensor’s dtype, which was good news. The surprise was that FlashAttention’s fp8 KV path requires sm_90 or higher (Hopper). On Ada (sm_89, my laptop), the Python wrapper accepts fp8 tensors at the boundary but the underlying kernel doesn’t exist. Result: silent corruption with no error.
A six-line hardware gate in the factory refuses the dangerous combination at config time:
if kv_dtype == torch.float8_e4m3fn and "fa" in attention_backend.split(",") \
and not is_sm90_supported():
raise ValueError("FP8 KV cache with FlashAttention requires sm_90+. Use --attn fi.")FlashInfer works fine on Ada. TRT-LLM should too, but I didn’t smoke-test it locally because of a page_size constraint that doesn’t fit the Qwen models I have on hand. Only FA needs the hardware gate. A useful reminder that “the API accepts my inputs” and “the kernel exists for my hardware” are different questions.
Seventy lines of plumbing
After all that validation, the implementation itself was almost anticlimactic. The pool came in at the planned 70 lines; the realised diff was 215 once you count the factory gate, the FlashInfer metadata split, the engine wiring, the regression tests, and the CLI flag. Each piece was small additive plumbing, but together they reflect how much surface area a “simple” new dtype actually touches.
The core class is twelve lines, simplified slightly for readability (the real __init__ enumerates the pool constructor’s parameters explicitly):
class QuantizedMHAKVCache(MHAKVCache):
def __init__(self, *, dtype, **kw):
super().__init__(dtype=torch.float8_e4m3fn, **kw)
self._compute_dtype = dtype
def store_kv(self, k, v, out_loc, layer_id):
k_q = k.clamp(-448.0, 448.0).to(torch.float8_e4m3fn)
v_q = v.clamp(-448.0, 448.0).to(torch.float8_e4m3fn)
super().store_kv(k_q, v_q, out_loc, layer_id)
@property
def dtype(self): return self._compute_dtype
@property
def store_dtype(self): return self._kv_buffer.dtypeCompute dtype comes in, fp8 bytes get stored, the parent class handles the byte copy. The cache manager and scheduler stay unaware of the dtype split; only the attention backend has to know about it, reading kvcache.dtype for Q and kvcache.store_dtype for K and V. The hot path:
%3btext-align:center%3b%7d%23mermaid-0 .edgeLabel p%7bbackground-color:rgba(232%2c232%2c232%2c 0.8)%3b%7d%23mermaid-0 .edgeLabel rect%7bopacity:0.5%3bbackground-color:rgba(232%2c232%2c232%2c 0.8)%3bfill:rgba(232%2c232%2c232%2c 0.8)%3b%7d%23mermaid-0 .labelBkg%7bbackground-color:rgba(232%2c 232%2c 232%2c 0.5)%3b%7d%23mermaid-0 .cluster rect%7bfill:%23ffffde%3bstroke:%23aaaa33%3bstroke-width:1px%3b%7d%23mermaid-0 .cluster text%7bfill:%23333%3b%7d%23mermaid-0 .cluster span%7bcolor:%23333%3b%7d%23mermaid-0 div.mermaidTooltip%7bposition:absolute%3btext-align:center%3bmax-width:200px%3bpadding:2px%3bfont-family:arial%2csans-serif%3bfont-size:12px%3bbackground:hsl(80%2c 100%25%2c 96.2745098039%25)%3bborder:1px solid %23aaaa33%3bborder-radius:2px%3bpointer-events:none%3bz-index:100%3b%7d%23mermaid-0 .flowchartTitleText%7btext-anchor:middle%3bfont-size:18px%3bfill:%23333%3b%7d%23mermaid-0 rect.text%7bfill:none%3bstroke-width:0%3b%7d%23mermaid-0 .icon-shape%2c%23mermaid-0 .image-shape%7bbackground-color:rgba(232%2c232%2c232%2c 0.8)%3btext-align:center%3b%7d%23mermaid-0 .icon-shape p%2c%23mermaid-0 .image-shape p%7bbackground-color:rgba(232%2c232%2c232%2c 0.8)%3bpadding:2px%3b%7d%23mermaid-0 .icon-shape .label rect%2c%23mermaid-0 .image-shape .label rect%7bopacity:0.5%3bbackground-color:rgba(232%2c232%2c232%2c 0.8)%3bfill:rgba(232%2c232%2c232%2c 0.8)%3b%7d%23mermaid-0 .label-icon%7bdisplay:inline-block%3bheight:1em%3boverflow:visible%3bvertical-align:-0.125em%3b%7d%23mermaid-0 .node .label-icon path%7bfill:currentColor%3bstroke:revert%3bstroke-width:revert%3b%7d%23mermaid-0 .node .neo-node%7bstroke:%239370DB%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node rect%2c%23mermaid-0 %5bdata-look='neo'%5d.cluster rect%2c%23mermaid-0 %5bdata-look='neo'%5d.node polygon%7bstroke:%239370DB%3bfilter:drop-shadow(1px 2px 2px rgba(185%2c 185%2c 185%2c 1))%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node path%7bstroke:%239370DB%3bstroke-width:1px%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node .outer-path%7bfilter:drop-shadow(1px 2px 2px rgba(185%2c 185%2c 185%2c 1))%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node .neo-line path%7bstroke:%239370DB%3bfilter:none%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node circle%7bstroke:%239370DB%3bfilter:drop-shadow(1px 2px 2px rgba(185%2c 185%2c 185%2c 1))%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node circle .state-start%7bfill:black%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.icon-shape .icon%7bfill:%239370DB%3bfilter:drop-shadow(1px 2px 2px rgba(185%2c 185%2c 185%2c 1))%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.icon-shape .icon-neo path%7bstroke:%239370DB%3bfilter:drop-shadow(1px 2px 2px rgba(185%2c 185%2c 185%2c 1))%3b%7d%23mermaid-0 :root%7b--mermaid-font-family:arial%2csans-serif%3b%7d%3c/style%3e%3cg%3e%3cmarker id='mermaid-0_flowchart-v2-pointEnd' class='marker flowchart-v2' viewBox='0 0 10 10' refX='5' refY='5' markerUnits='userSpaceOnUse' markerWidth='8' markerHeight='8' orient='auto'%3e%3cpath d='M 0 0 L 10 5 L 0 10 z' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-pointStart' class='marker flowchart-v2' viewBox='0 0 10 10' refX='4.5' refY='5' markerUnits='userSpaceOnUse' markerWidth='8' markerHeight='8' orient='auto'%3e%3cpath d='M 0 5 L 10 10 L 10 0 z' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-pointEnd-margin' class='marker flowchart-v2' viewBox='0 0 11.5 14' refX='11.5' refY='7' markerUnits='userSpaceOnUse' markerWidth='10.5' markerHeight='14' orient='auto'%3e%3cpath d='M 0 0 L 11.5 7 L 0 14 z' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-pointStart-margin' class='marker flowchart-v2' viewBox='0 0 11.5 14' refX='1' refY='7' markerUnits='userSpaceOnUse' markerWidth='11.5' markerHeight='14' orient='auto'%3e%3cpolygon points='0%2c7 11.5%2c14 11.5%2c0' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-circleEnd' class='marker flowchart-v2' viewBox='0 0 10 10' refX='11' refY='5' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-circleStart' class='marker flowchart-v2' viewBox='0 0 10 10' refX='-1' refY='5' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-circleEnd-margin' class='marker flowchart-v2' viewBox='0 0 10 10' refY='5' refX='12.25' markerUnits='userSpaceOnUse' markerWidth='14' markerHeight='14' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-circleStart-margin' class='marker flowchart-v2' viewBox='0 0 10 10' refX='-2' refY='5' markerUnits='userSpaceOnUse' markerWidth='14' markerHeight='14' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-crossEnd' class='marker cross flowchart-v2' viewBox='0 0 11 11' refX='12' refY='5.2' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3cpath d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9' class='arrowMarkerPath' style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-crossStart' class='marker cross flowchart-v2' viewBox='0 0 11 11' refX='-1' refY='5.2' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3cpath d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9' class='arrowMarkerPath' style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-crossEnd-margin' class='marker cross flowchart-v2' viewBox='0 0 15 15' refX='17.7' refY='7.5' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto'%3e%3cpath d='M 1%2c1 L 14%2c14 M 1%2c14 L 14%2c1' class='arrowMarkerPath' style='stroke-width: 2.5%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-crossStart-margin' class='marker cross flowchart-v2' viewBox='0 0 15 15' refX='-3.5' refY='7.5' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto'%3e%3cpath d='M 1%2c1 L 14%2c14 M 1%2c14 L 14%2c1' class='arrowMarkerPath' style='stroke-width: 2.5%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cg class='root'%3e%3cg class='clusters'%3e%3cg class='cluster' id='mermaid-0-qpool' data-look='classic'%3e%3crect style='' x='173.15625' y='40.630165100097656' width='494.6875' height='208'/%3e%3cg class='cluster-label' transform='translate(246.1953125%2c 40.630165100097656)'%3e%3cforeignObject width='348.609375' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eQuantizedMHAKVCache.store_kv (new%2c 12 lines)%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='edgePaths'%3e%3cpath d='M900.367%2c35L919.026%2c35C937.685%2c35%2c975.003%2c35%2c1009.84%2c47.204C1044.678%2c59.407%2c1077.035%2c83.814%2c1093.214%2c96.018L1109.392%2c108.221' id='mermaid-0-L_Q_RUN_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_Q_RUN_0' data-points='W3sieCI6OTAwLjM2NzE4NzUsInkiOjM1fSx7IngiOjEwMTIuMzIwMzEyNSwieSI6MzV9LHsieCI6MTExMi41ODU1NTgwNjE4MzkzLCJ5IjoxMTAuNjMwMTY1MTAwMDk3NjZ9XQ==' data-look='classic' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3cpath d='M123.156%2c97.63L127.323%2c97.63C131.49%2c97.63%2c139.823%2c97.63%2c148.156%2c97.63C156.49%2c97.63%2c164.823%2c97.63%2c172.566%2c99.501C180.308%2c101.371%2c187.46%2c105.113%2c191.036%2c106.983L194.612%2c108.854' id='mermaid-0-L_K_CAST_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_K_CAST_0' data-points='W3sieCI6MTIzLjE1NjI1LCJ5Ijo5Ny42MzAxNjUxMDAwOTc2Nn0seyJ4IjoxNDguMTU2MjUsInkiOjk3LjYzMDE2NTEwMDA5NzY2fSx7IngiOjE3My4xNTYyNSwieSI6OTcuNjMwMTY1MTAwMDk3NjZ9LHsieCI6MTk4LjE1NjI1LCJ5IjoxMTAuNzA3ODEzNjM4MjkzMTl9XQ==' data-look='classic' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3cpath d='M123.156%2c201.63L127.323%2c201.63C131.49%2c201.63%2c139.823%2c201.63%2c148.156%2c201.63C156.49%2c201.63%2c164.823%2c201.63%2c172.566%2c199.76C180.308%2c197.889%2c187.46%2c194.148%2c191.036%2c192.277L194.612%2c190.407' id='mermaid-0-L_V_CAST_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_V_CAST_0' data-points='W3sieCI6MTIzLjE1NjI1LCJ5IjoyMDEuNjMwMTY1MTAwMDk3NjZ9LHsieCI6MTQ4LjE1NjI1LCJ5IjoyMDEuNjMwMTY1MTAwMDk3NjZ9LHsieCI6MTczLjE1NjI1LCJ5IjoyMDEuNjMwMTY1MTAwMDk3NjZ9LHsieCI6MTk4LjE1NjI1LCJ5IjoxODguNTUyNTE2NTYxOTAyMX1d' data-look='classic' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3cpath d='M346.969%2c149.63L351.135%2c149.63C355.302%2c149.63%2c363.635%2c149.63%2c371.302%2c149.63C378.969%2c149.63%2c385.969%2c149.63%2c389.469%2c149.63L392.969%2c149.63' id='mermaid-0-L_CAST_SC_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_CAST_SC_0' data-points='W3sieCI6MzQ2Ljk2ODc1LCJ5IjoxNDkuNjMwMTY1MTAwMDk3NjZ9LHsieCI6MzcxLjk2ODc1LCJ5IjoxNDkuNjMwMTY1MTAwMDk3NjZ9LHsieCI6Mzk2Ljk2ODc1LCJ5IjoxNDkuNjMwMTY1MTAwMDk3NjZ9XQ==' data-look='classic' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3cpath d='M642.844%2c149.63L647.01%2c149.63C651.177%2c149.63%2c659.51%2c149.63%2c667.844%2c149.63C676.177%2c149.63%2c684.51%2c149.63%2c703.104%2c149.63C721.698%2c149.63%2c750.552%2c149.63%2c764.979%2c149.63L779.406%2c149.63' id='mermaid-0-L_SC_BUF_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_SC_BUF_0' data-points='W3sieCI6NjQyLjg0Mzc1LCJ5IjoxNDkuNjMwMTY1MTAwMDk3NjZ9LHsieCI6NjY3Ljg0Mzc1LCJ5IjoxNDkuNjMwMTY1MTAwMDk3NjZ9LHsieCI6NjkyLjg0Mzc1LCJ5IjoxNDkuNjMwMTY1MTAwMDk3NjZ9LHsieCI6NzgzLjQwNjI1LCJ5IjoxNDkuNjMwMTY1MTAwMDk3NjZ9XQ==' data-look='classic' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3cpath d='M900.406%2c149.63L919.059%2c149.63C937.711%2c149.63%2c975.016%2c149.63%2c1000.727%2c149.63C1026.438%2c149.63%2c1040.555%2c149.63%2c1047.613%2c149.63L1054.672%2c149.63' id='mermaid-0-L_BUF_RUN_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_BUF_RUN_0' data-points='W3sieCI6OTAwLjQwNjI1LCJ5IjoxNDkuNjMwMTY1MTAwMDk3NjZ9LHsieCI6MTAxMi4zMjAzMTI1LCJ5IjoxNDkuNjMwMTY1MTAwMDk3NjZ9LHsieCI6MTA1OC42NzE4NzUsInkiOjE0OS42MzAxNjUxMDAwOTc2Nn1d' data-look='classic' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3cpath d='M965.969%2c276.26L973.694%2c276.26C981.419%2c276.26%2c996.87%2c276.26%2c1021.61%2c262.082C1046.351%2c247.904%2c1080.382%2c219.547%2c1097.397%2c205.369L1114.412%2c191.191' id='mermaid-0-L_PLAN_RUN_0' class='edge-thickness-normal edge-pattern-dotted edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_PLAN_RUN_0' data-points='W3sieCI6OTY1Ljk2ODc1LCJ5IjoyNzYuMjYwMzMwMjAwMTk1M30seyJ4IjoxMDEyLjMyMDMxMjUsInkiOjI3Ni4yNjAzMzAyMDAxOTUzfSx7IngiOjExMTcuNDg1MTk2NzI4MjQ2MSwieSI6MTg4LjYzMDE2NTEwMDA5NzY2fV0=' data-look='classic' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3cpath d='M1269.906%2c149.63L1274.073%2c149.63C1278.24%2c149.63%2c1286.573%2c149.63%2c1294.24%2c149.63C1301.906%2c149.63%2c1308.906%2c149.63%2c1312.406%2c149.63L1315.906%2c149.63' id='mermaid-0-L_RUN_OUT_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_RUN_OUT_0' data-points='W3sieCI6MTI2OS45MDYyNSwieSI6MTQ5LjYzMDE2NTEwMDA5NzY2fSx7IngiOjEyOTQuOTA2MjUsInkiOjE0OS42MzAxNjUxMDAwOTc2Nn0seyJ4IjoxMzE5LjkwNjI1LCJ5IjoxNDkuNjMwMTY1MTAwMDk3NjZ9XQ==' data-look='classic' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3c/g%3e%3cg class='edgeLabels'%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_Q_RUN_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_K_CAST_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_V_CAST_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_CAST_SC_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_SC_BUF_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_BUF_RUN_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel' transform='translate(1012.3203125%2c 276.2603302001953)'%3e%3cg class='label' data-id='L_PLAN_RUN_0' transform='translate(-21.3515625%2c -12)'%3e%3cforeignObject width='42.703125' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3cp%3econfig%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_RUN_OUT_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='nodes'%3e%3cg class='node default' id='mermaid-0-flowchart-Q-0' data-look='classic' transform='translate(841.90625%2c 35)'%3e%3crect class='basic label-container' style='' x='-58.4609375' y='-27' width='116.921875' height='54'/%3e%3cg class='label' style='' transform='translate(-28.4609375%2c -12)'%3e%3crect/%3e%3cforeignObject width='56.921875' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eQ %c2%b7 fp16%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-0-flowchart-RUN-1' data-look='classic' transform='translate(1164.2890625%2c 149.63016510009766)'%3e%3crect class='basic label-container' style='' x='-105.6171875' y='-39' width='211.234375' height='78'/%3e%3cg class='label' style='' transform='translate(-75.6171875%2c -24)'%3e%3crect/%3e%3cforeignObject width='151.234375' height='48'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eFlashInfer.run()%3cbr /%3edequant K%2c V on read%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-0-flowchart-K-2' data-look='classic' transform='translate(65.578125%2c 97.63016510009766)'%3e%3crect class='basic label-container' style='' x='-57.578125' y='-27' width='115.15625' height='54'/%3e%3cg class='label' style='' transform='translate(-27.578125%2c -12)'%3e%3crect/%3e%3cforeignObject width='55.15625' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eK %c2%b7 fp16%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-0-flowchart-CAST-3' data-look='classic' transform='translate(272.5625%2c 149.63016510009766)'%3e%3crect class='basic label-container' style='' x='-74.40625' y='-39' width='148.8125' height='78'/%3e%3cg class='label' style='' transform='translate(-44.40625%2c -24)'%3e%3crect/%3e%3cforeignObject width='88.8125' height='48'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eclamp(%c2%b1448)%3cbr /%3e%2b .to(fp8)%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-0-flowchart-V-4' data-look='classic' transform='translate(65.578125%2c 201.63016510009766)'%3e%3crect class='basic label-container' style='' x='-57.578125' y='-27' width='115.15625' height='54'/%3e%3cg class='label' style='' transform='translate(-27.578125%2c -12)'%3e%3crect/%3e%3cforeignObject width='55.15625' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eV %c2%b7 fp16%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-0-flowchart-SC-7' data-look='classic' transform='translate(519.90625%2c 149.63016510009766)'%3e%3crect class='basic label-container' style='' x='-122.9375' y='-39' width='245.875' height='78'/%3e%3cg class='label' style='' transform='translate(-92.9375%2c -24)'%3e%3crect/%3e%3cforeignObject width='185.875' height='48'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3esuper().store_kv()%3cbr /%3ebyte-copy via store_cache%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-0-flowchart-BUF-9' data-look='classic' transform='translate(841.90625%2c 149.63016510009766)'%3e%3cpath d='M0%2c12.086776859504132 a58.5%2c12.086776859504132 0%2c0%2c0 117%2c0 a58.5%2c12.086776859504132 0%2c0%2c0 -117%2c0 l0%2c51.086776859504134 a58.5%2c12.086776859504132 0%2c0%2c0 117%2c0 l0%2c-51.086776859504134' class='basic label-container outer-path' style='' transform='translate(-58.5%2c -37.6301652892562)'/%3e%3cg class='label' style='' transform='translate(-51%2c -2)'%3e%3crect/%3e%3cforeignObject width='102' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eKV buffer %c2%b7 fp8%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-0-flowchart-PLAN-12' data-look='classic' transform='translate(841.90625%2c 276.2603302001953)'%3e%3crect class='basic label-container' style='' x='-124.0625' y='-39' width='248.125' height='78'/%3e%3cg class='label' style='' transform='translate(-94.0625%2c -24)'%3e%3crect/%3e%3cforeignObject width='188.125' height='48'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eFIMetadata.kv_dtype%3cbr /%3e%e2%86%92 plan(kv_data_type=fp8)%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-0-flowchart-OUT-15' data-look='classic' transform='translate(1416.1796875%2c 149.63016510009766)'%3e%3crect class='basic label-container' style='' x='-96.2734375' y='-27' width='192.546875' height='54'/%3e%3cg class='label' style='' transform='translate(-66.2734375%2c -12)'%3e%3crect/%3e%3cforeignObject width='132.546875' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eattention out %c2%b7 fp16%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cdefs%3e%3cfilter id='mermaid-0-drop-shadow' height='130%25' width='130%25'%3e%3cfeDropShadow dx='4' dy='4' stdDeviation='0' flood-opacity='0.06' flood-color='black'/%3e%3c/filter%3e%3c/defs%3e%3cdefs%3e%3cfilter id='mermaid-0-drop-shadow-small' height='150%25' width='150%25'%3e%3cfeDropShadow dx='2' dy='2' stdDeviation='0' flood-opacity='0.06' flood-color='black'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)
The factory also fires a loud rank-0 startup warning naming the v1 caveat (uncalibrated scales) so users on W8A8 checkpoints can’t claim they weren’t warned. Total diff: 215 lines across 9 files (7 modified, 2 new), of which 135 is implementation and 80 is tests and logging. Zero CUDA. Code review caught three real improvements I’m happy to credit: collapsing duplicated factory branches, making store_kv call super().store_kv() rather than reaching into private buffers, and using the existing is_sm90_supported() utility instead of open-coding the device check.
What fp8 actually delivers
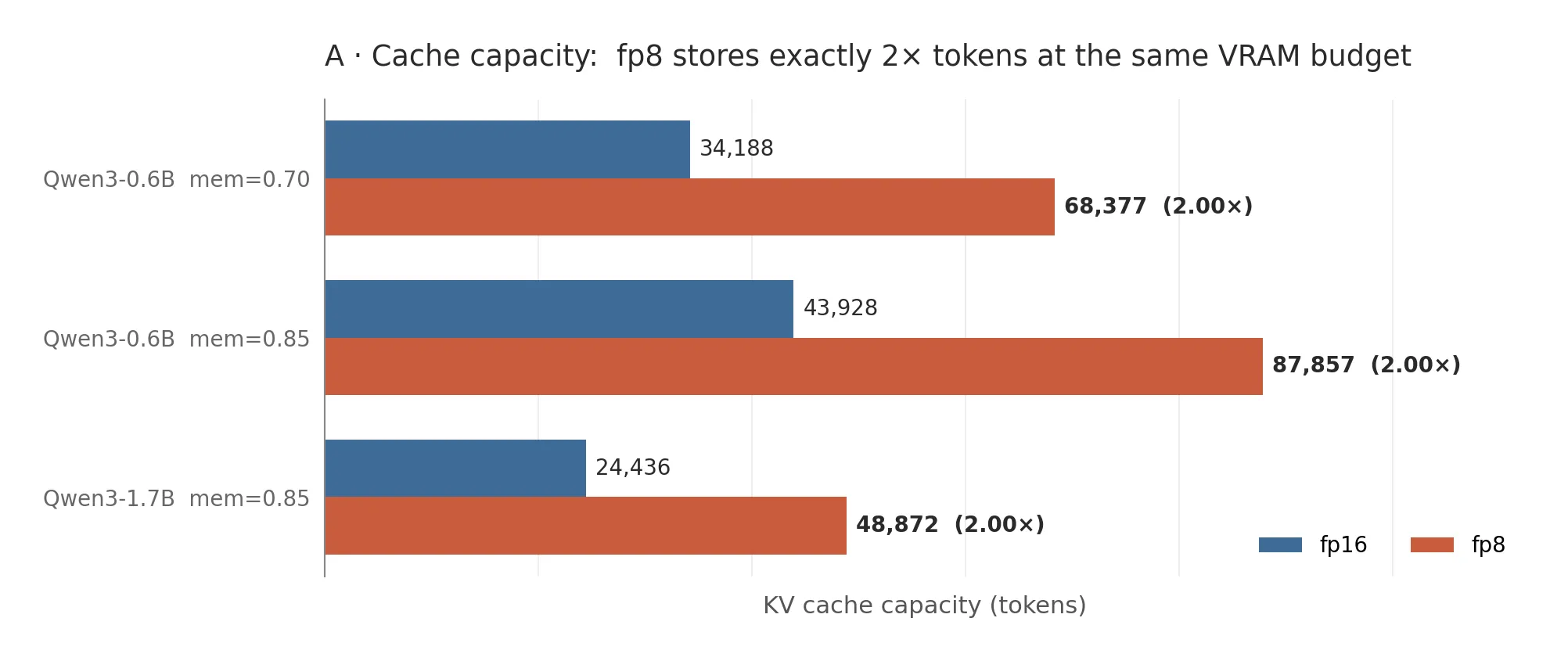
Memory capacity, every config tested, is exactly 2x. Qwen3-0.6B goes from 43,928 cached tokens to 87,857; Qwen3-1.7B from 24,436 to 48,872. Hardware-independent, deterministic, exact.
Latency, on Qwen3-0.6B:
| Workload | ITL median win | Throughput win |
|---|---|---|
| in=512, conc=8 | -5.5% | +3.4% |
| in=2048, conc=8 | -15.2% | +9.4% |
| in=4096, conc=4 | -15.8% | +10.1% |
| in=8192, conc=2 | -24.3% | +11.1% |
| out=1024, conc=8 | -14.7% | +14.9% |
| conc=20 | -26.8% | +21.1% |
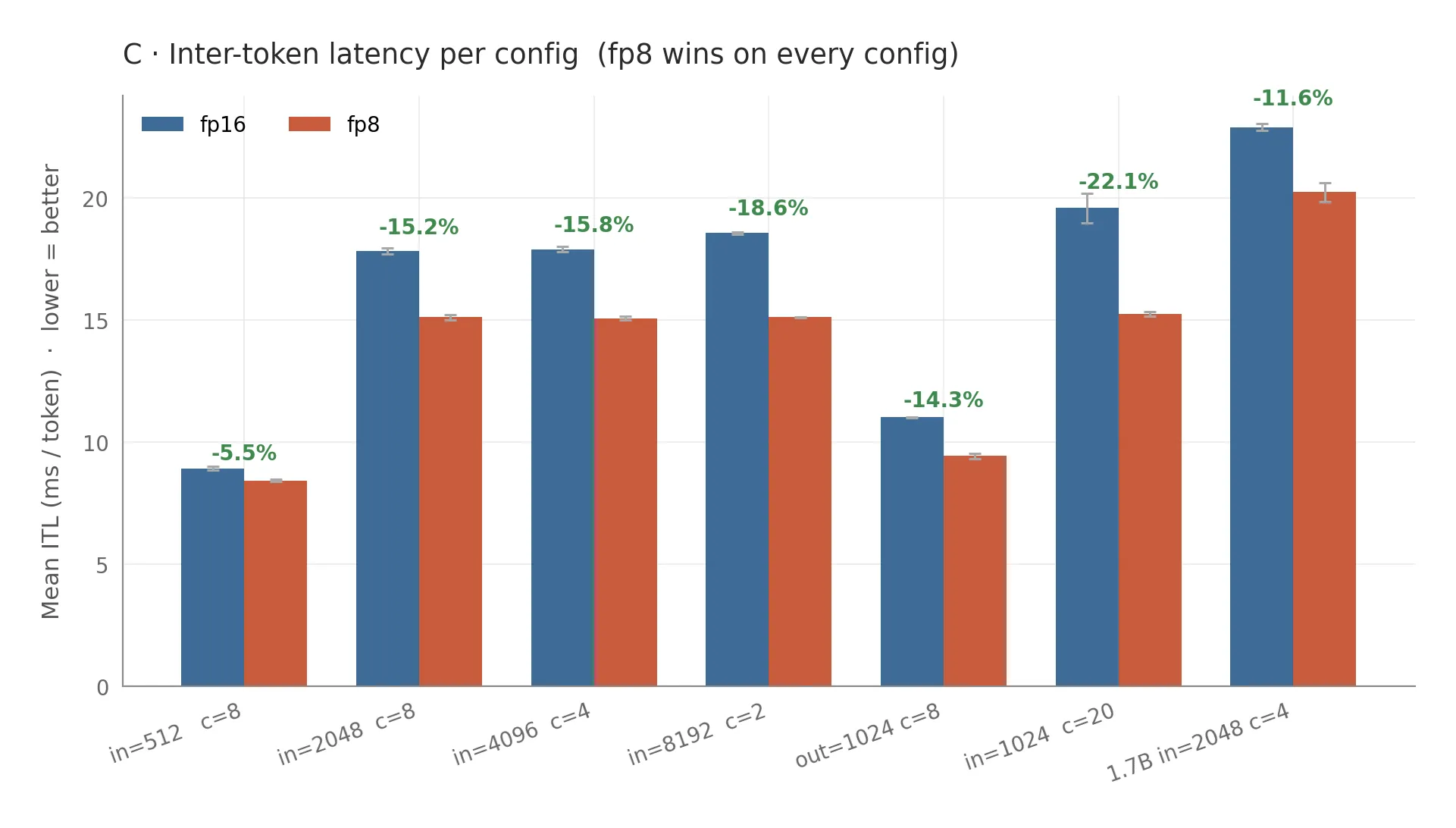
Monotonic: more memory pressure, bigger win. At high concurrency, fp8 delivers a 27 percent median ITL reduction, within striking distance of the theoretical 2x bandwidth ceiling.
The honest cost is that TTFT regresses by 4 to 12 percent on every config. In eager mode, k.clamp(...) and k.to(fp8) are two unfused kernel launches, times K and V, times 28 layers, for every prefill token. Pure scheduling overhead during a phase where the cache isn’t even being read.
Whether that matters depends on the workload:
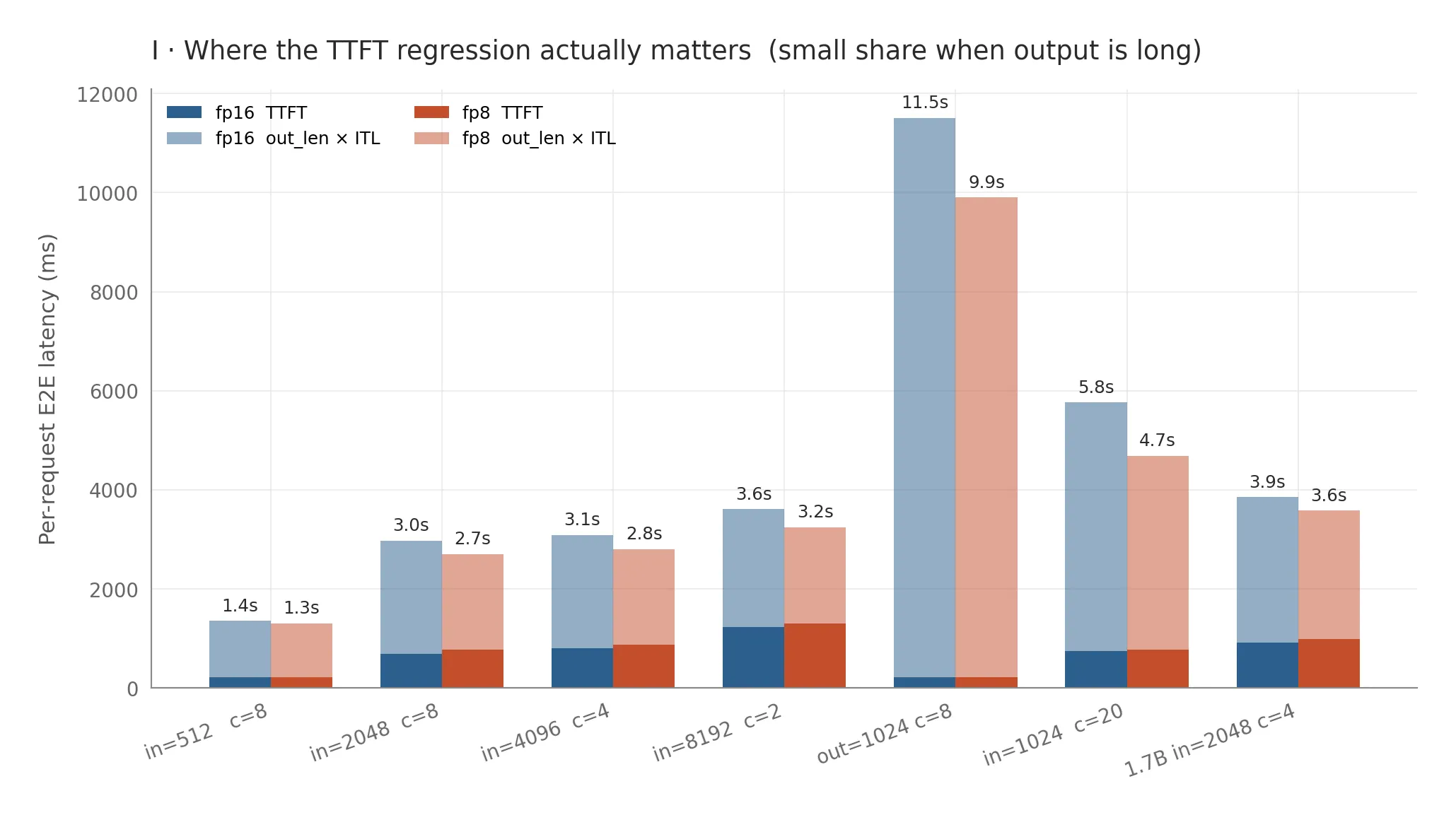
For long-form generation (out=1024), TTFT is 1.9 percent of E2E latency in fp16 and 2.3 percent in fp8: real but invisible because decode swamps it. For short interactive completions where TTFT is 30 to 50 percent of E2E, the regression is noticeable. Every workload tested ends up net-faster end-to-end, but where the win comes from varies.
The fix is a fused Triton kernel that combines clamp, cast, and the cache scatter into one launch (around 50 lines, entirely additive). Every production engine has done this; vLLM added theirs in v0.4 after shipping the unfused version first. Same arc as this PR.
The honest read is that the fp8 KV speedup is bounded by how memory-bound the read path actually is on your hardware. On a small model on a compute-rich consumer GPU at modest context, that bound is single-digit to low-double-digit percentages. On a 70B model on H100 with 32k context and 64-way concurrency, every factor pushes harder into the memory-bound regime and the same code path delivers the 30 to 40 percent throughput numbers the marketing material implies. Same code, very different operating point. v2 will validate this on H100 via cloud rental, which also unlocks the FA + fp8 path the Ada gate currently refuses.
The capacity win is hardware-independent. Twice as many concurrent users or twice as long a context at the same VRAM is the actual production headline regardless of GPU.
Does fp8 hurt accuracy?
Latency wins are cheap if outputs are nonsense, so this was the question I cared most about getting right.
I started with the obvious test, which turned out to be the wrong test: 22 prompts at temperature=0 against fp16 and fp8, checking whether outputs match. Zero out of 22 token-identical, with mean prefix agreement of only 12 percent.
That sounds alarming but isn’t. Greedy decoding makes any logit perturbation immediately visible, and the moment fp8 noise flips a single near-tie, the trajectory diverges and never reconverges. Qwen3-0.6B is a reasoning model emitting long <think> chains, so each response has hundreds of near-tie decisions, each one a flip opportunity. Path identity is the wrong metric for FP8 KV; the real question is whether the divergent trajectories still arrive at the same answer.
To answer that, I picked two industry-standard benchmarks. GSM8K-200 (grade-school math, numeric ground truth) tests reasoning quality. NIAH (Needle in a Haystack) probes KV cache fidelity directly: insert a number into a long context, ask the model to retrieve it.
GSM8K:
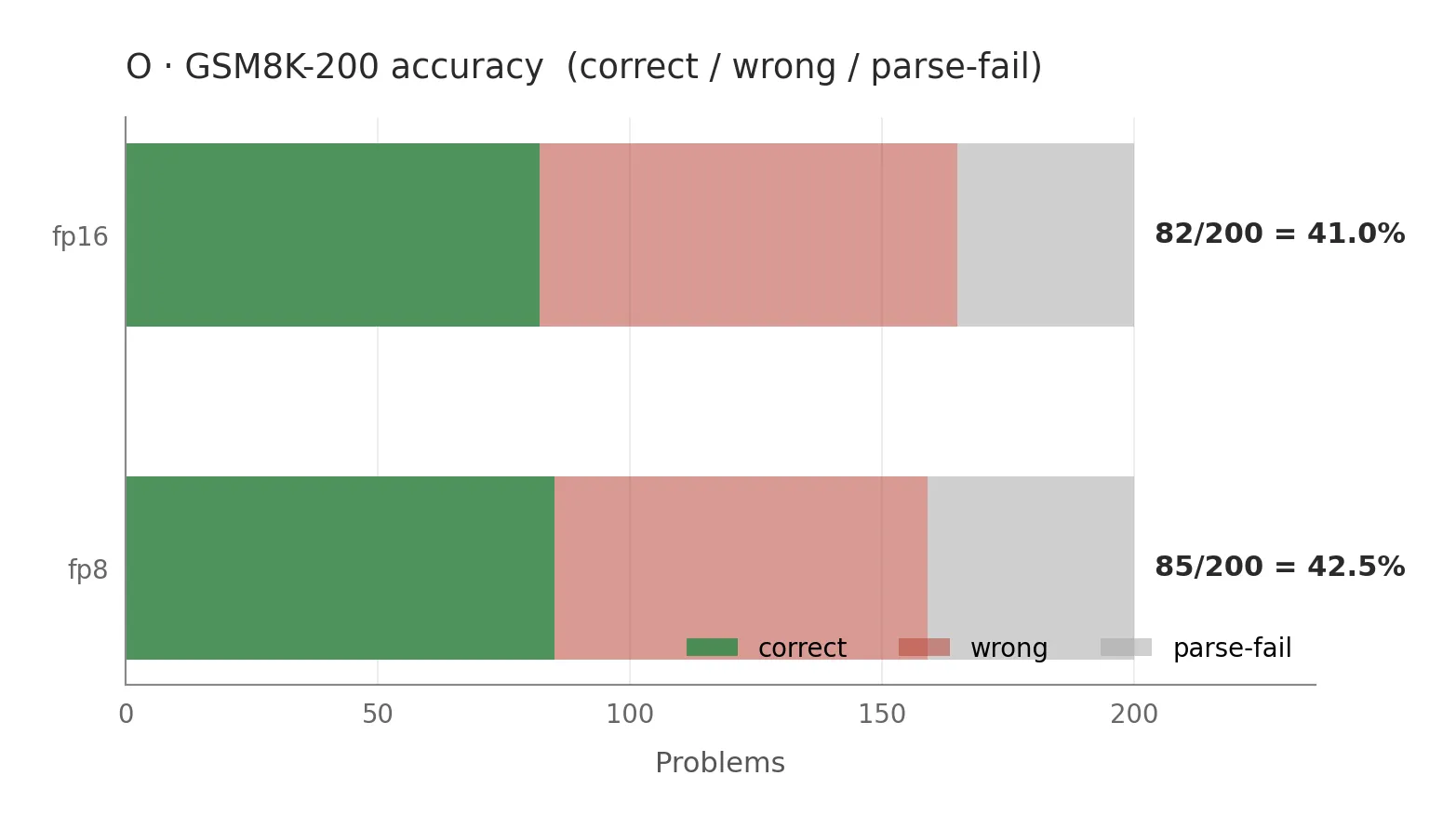
42.5 percent (fp8) versus 41.0 percent (fp16). At n=200 the confidence interval is roughly ±5 percentage points, so this is within noise. The defensible claim is no regression.
The interesting finding was the contingency:
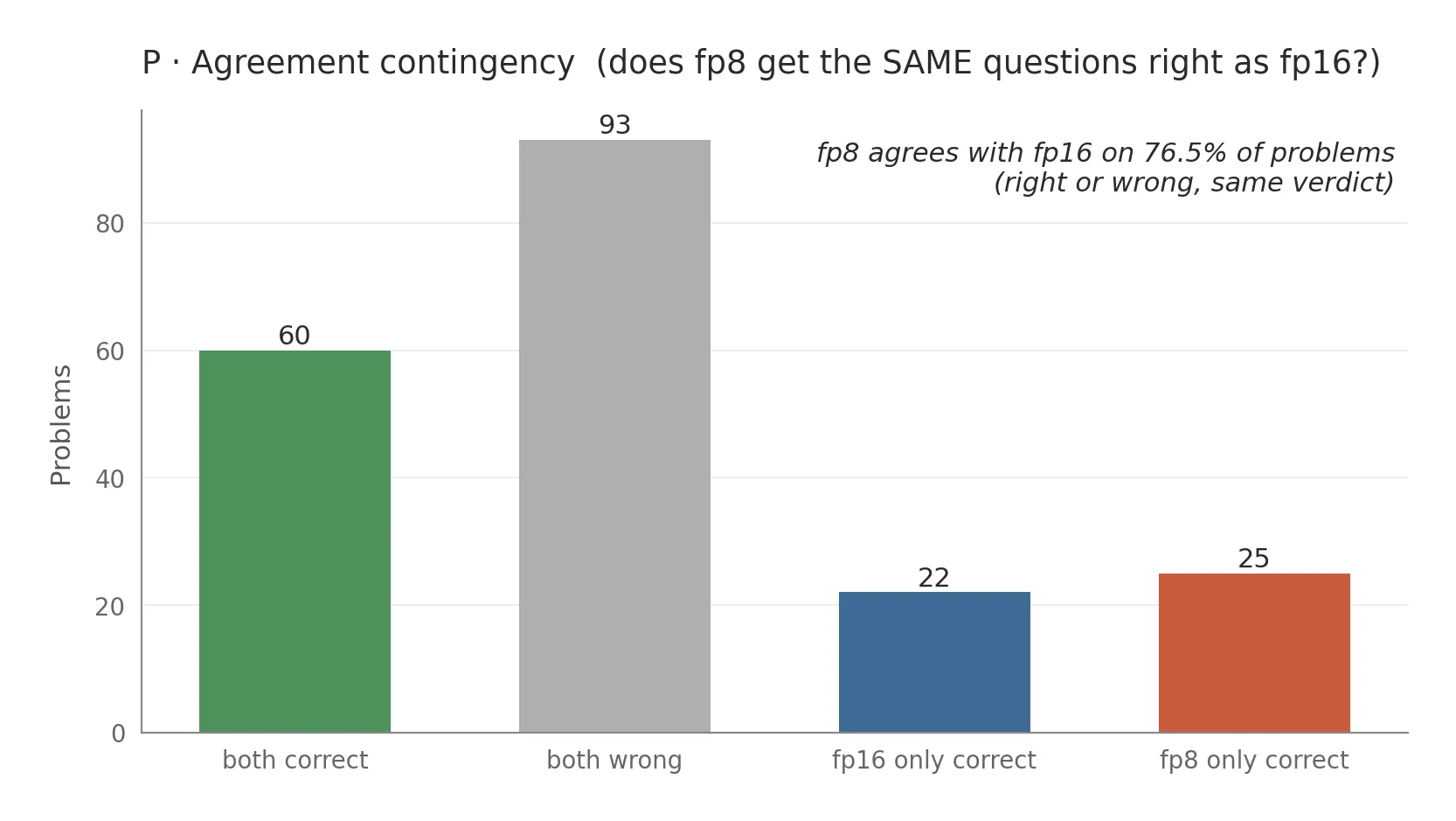
Of the 47 problems where fp8 and fp16 disagree, fp16 wins 22 and fp8 wins 25. The disagreement is symmetric, so fp8 isn’t systematically degrading the model; it’s perturbing the decision boundary in a balanced way. This refuted an intuition I’d been carrying that fp8 paths differing must mean fp8 was wrong more often. Paths differ (0 of 22 token match) but verdicts agree 76.5 percent of the time with no bias.
NIAH was the strongest result:
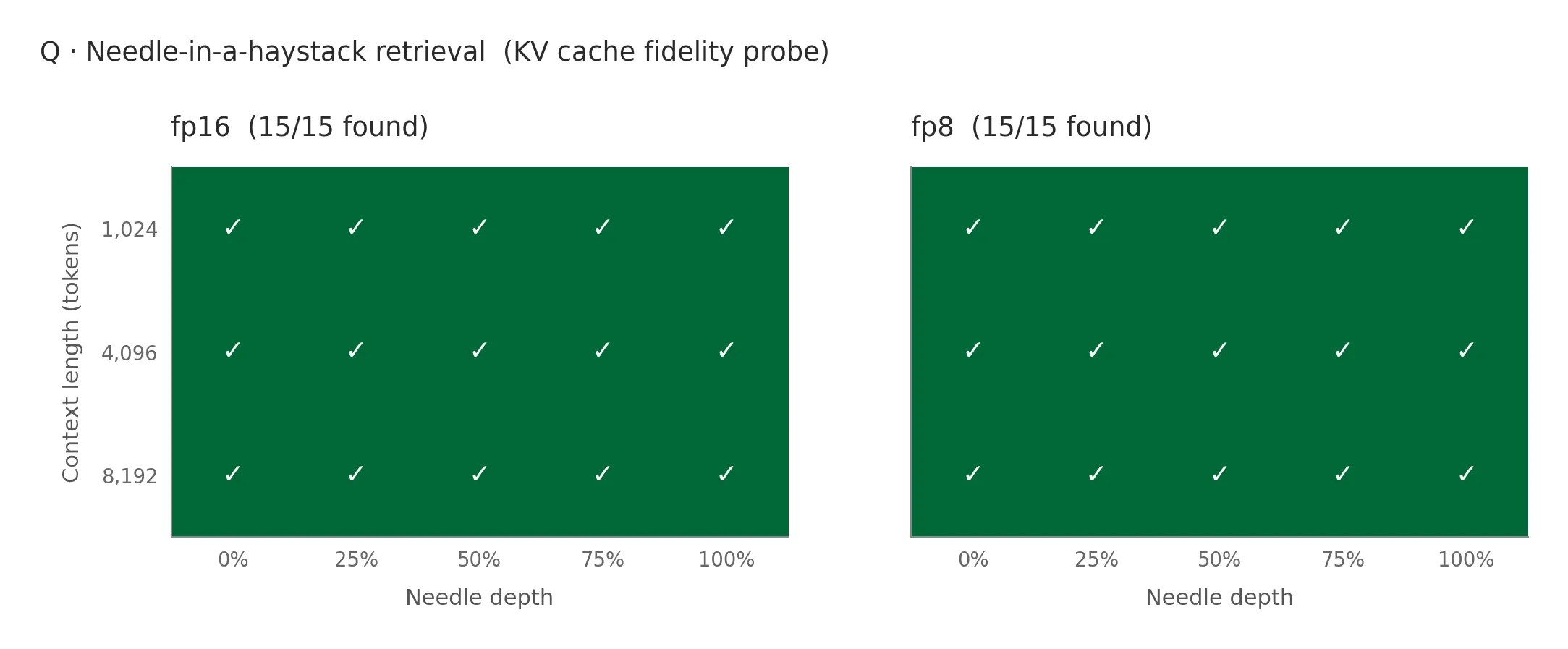
Fifteen probes per dtype across three context lengths and five needle depths. fp8 retrieves the needle perfectly at every position, including the 50 percent depth at 8k tokens (“lost in the middle”), which is where KV quantisation typically degrades most. The clamp(±448).to(fp8) quantisation is precise enough.
The v1 quality story ended up strong across the board: no NaN, output lengths track fp16, no GSM8K regression, perfect NIAH retrieval. That’s the strongest position v1 can hold without calibrated scales.
What this taught me
Three habits I want to carry forward.
Validate the contract before writing the code. Phase 0 cost an hour and caught a NaN bug that would have made production debugging miserable. The discipline I apply now: ask of any plan what the one load-bearing assumption is, then find the cheapest possible test for it.
Look for codebase precedent before inventing patterns. The question of whether store_dtype should be abstract on the base class had a precedent staring at me from BaseOP, which uses abstract-core-plus-concrete-defaults exactly where my pool wanted to. Established codebases have a grammar, and reading a few neighbouring files before writing your own is almost always cheaper than figuring it out from scratch.
Name what’s deferred and why, in the PR itself. The loud warning, the regression test pinning the NaN trap, and the explicit non-goals list all exist so nobody (including me) can quietly forget what was traded away.
And one result rather than a habit: FP8 KV cache isn’t a magic latency button. It’s an exact capacity halving plus a theory-bounded latency win that scales with workload pressure. Same code, different operating point. That framing took me a while to internalise, and it’s the most useful thing I have to say to anyone reading FP8 benchmarks elsewhere: ask what the workload was.
What’s deferred
The fused Triton kernel (around 50 lines) closes the TTFT regression. Calibrated k_scale/v_scale from W8A8 checkpoints (around 100 lines) is plumbing, not new kernels. TRT-LLM smoke test is locally untested due to a page_size constraint. H100 validation, including the FA + fp8 path the sm_90 gate currently refuses on Ada and an extended quality eval at 16k+ context, is planned for v2 via short cloud rental.
INT8 KV cache is deliberately not on the roadmap: it doesn’t have a clean “scale equals 1.0” starting point the way FP8 does, because it needs calibrated per-tensor scales from day one to retain enough dynamic range. That makes it a substantially bigger project, so I’d treat it as its own effort rather than a continuation of this one.